Business Intelligence is al jaren niet meer weg te denken in de IT wereld. Organisaties zien steeds meer in hoeveel data ze bezitten en wat ze er eigenlijk mee kunnen doen als ze dit ten volste zouden benutten. Rapportages, dashboards, wettelijke regelgeving, van allerhande middelen zijn er ontwikkeld om waarde te halen uit data en er vervolgens op te sturen.
Het data warehouse, de onderliggende bak aan data ligt daar in veel gevallen aan ten grondslag. Op een gestructureerde manier wordt data ontsloten uit de verschillende bronnen en opgeslagen in een data model zodat de eerder genoemde producten ontwikkeld kunnen worden. Die techniek staat ook al vele jaren, is doorontwikkeld maar in de basis nog altijd hetzelfde. Er wordt data ontsloten (Extract), het wordt naar het juiste formaat gebracht (Transform) en uiteindelijk geladen (Load).
Echter, de algemene tendens van de laatste jaren is dat cloud oplossingen steeds meer zijn intrede doen. Dat geldt ook zeker voor data gerelateerde toepassingen. Organisaties zien hier steeds meer de voordelen van in en maken makkelijker de stap van een on-premise oplossing naar een volledig in de cloud data & analytics platform. Bij mijn opdrachtgever is die stap al enige tijd geleden gemaakt en draait het volledige data warehouse inmiddels in de cloud van Microsoft Azure. Slim, want door het gebruik van deze oplossing komen steeds meer voordelen van nieuwe toepassingen eenvoudig voor handen. Vervolgens wordt de data specialisten de ruimte gegeven om die mogelijkheden te ontdekken zodat deze op een juiste manier ingezet kunnen worden in de organisatie.
Een win-win situatie want tenslotte leert de data specialist nieuwe vaardigheden en voegt tegelijkertijd waarde toe aan het bestaande data platform. Door die ontwikkeling en de daarbij behorende ruimte is mijn interesse de laatste tijd steeds meer gewekt door de gedachte achter het lakehouse, een modernere vorm van het opslaan en verwerken van data, met een achterliggende visie die bedacht is door de organisatie achter Microsoft Azure Databricks. Concreet is het een platform voor gegevens analyse welke geoptimaliseerd is voor het Microsoft Azure Cloud platform.
Na enige research te hebben gedaan op het internet ben ik meer te weten gekomen over het concept, het idee en de techniek erachter. Dit leverde echter ook direct enkele vragen op, want: hoe verhoudt een lakehouse zich tot een data warehouse en wat zijn de voordelen van het ene of het andere concept? Wat is de achterliggende techniek en hoe makkelijk is het te implementeren in organisaties met een bestaande Data Management & Business Intelligence omgeving?
En belangrijker: is dit de toekomst of is dit een buzzword die uiteindelijk weer in de vergetelheid raakt? In dit blog schets ik de context, de achtergrond en geef ik antwoord op de eerder genoemde vragen.

Een aantal jaar geleden zag het data landschap er nog vrij eenvoudig uit. Binnen organisaties waren er een aantal systemen om gegevens in op te slaan. Gestructureerd, in een database en conform een vast model. Door deze data bronnen te combineren ontstond het data warehouse en konden er door het toepassen van Business Intelligence technieken nieuwe inzichten gecreëerd worden waardoor er slim gestuurd kon worden op de uitkomsten hiervan. De digitale revolutie ging echter snel en de laatste jaren zijn organisaties steeds grotere hoeveelheden data gaan verzamelen, zowel gestructureerd als ongestructureerd. In verschillende systemen en in verschillende formaten. Waar eerst de nadruk lag op rapportage en sturing veranderde dit meer en meer naar analyse en voorspellingen. Op basis van die ontwikkelingen werd het data lake geïntroduceerd. Een grote verzamelplaats van alle data binnen een organisatie en eventueel ook daarbuiten, ongestructureerd opgeslagen zonder een bepaalde context of vastgelegd in een data model. Het doel van het data lake is om data los te koppelen van bedrijfsprocessen en in tegenstelling tot een data warehouse de data bijvoorbeeld niet te harmoniseren per afdeling maar ruw op te slaan. Op die manier wordt de mogelijkheid gecreëerd om data vanuit meerdere invalshoeken te benaderen in plaats van de data aan de hand van een data model, en in het eerdere voorbeeld per afdeling te analyseren.
Zo’n data lake werd in eerste instantie vaak naast het data warehouse geplaatst. Eerst als proeftuin om te kijken wat er allemaal mogelijk was maar door het gebruik van bijvoorbeeld foto’s, video’s, e-mails, klantgesprekken en data vanuit Social Media, kortom de opkomst van meer ongestructureerde data en de introductie van nieuwe rollen zoals die van een Data Scientist en technieken zoals Machine Learning & Artificial Intelligence kreeg het data lake een steeds prominentere rol in het data landschap. Echter, zaten er ook aan een data lake de nodige nadelen ten opzichte van een data warehouse. Een data lake legt bijvoorbeeld geen transacties vast, bouwt geen historie op en stelt nagenoeg geen eisen aan de kwaliteit van de data.
Daar waar een data warehouse dus vooral gericht is op gestructureerde data en historie en je voornamelijk interne systemen aansluit, is een data lake met name gericht op volume en ongestructureerde data en ben je in staat om waardevolle informatie vanuit bijvoorbeeld data van Funda, vanuit callcenters of enquêtes toe te voegen. De gedachtes achter beide concepten zijn uitstekend maar wanneer deze oplossingen worden samengevoegd creëer je een nog betere totaaloplossing. En dat is met name de laatste jaren ook gebeurd. De organisatie achter Microsoft Azure Databricks heeft het data warehouse en het data lake als uitgangspunt gepakt en een visie ontwikkeld om beide werelden met elkaar te verenigen en zo het lakehouse te ontwikkelen.
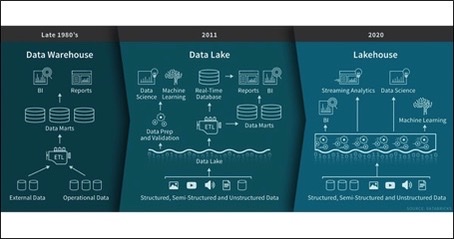
Kijkend naar de gedachte dan is deze eigenlijk vrij simpel, er is tegenwoordig namelijk steeds meer behoefte aan een flexibele en schaalbare oplossing. Een oplossing waar op een agile manier aan ontwikkeld kan worden en die zorgt voor het beschikbaar maken van toepassingen zoals SQL analyse, het uitvoeren van standaard rapportages en het toepassen van Data Science en Machine Learning. Waar je hier tot op heden een data warehouse én een data lake voor nodig had kan met het opzetten van een lakehouse ‘the best of both worlds’ gecreëerd worden.
Een platform dus waarbij zowel data (Business Intelligence) als analytics (Data Science) volledig ondersteund kan worden en zodoende de voordelen van het data warehouse (gestructureerd, data management) en het data lake (ongestructureerd, opslag) optimaal kunnen worden benut.
Realistisch kijkend naar de bestaande situatie bij organisaties dan draait er vaak al een data warehouse of data lake oplossing in de organisatie. Het zal in zo’n geval niet makkelijk zijn en wat mij betreft is het ook niet te adviseren om zo’n bestaande data warehouse of data lake oplossing direct om te bouwen naar het concept van een lakehouse. Dat is simpelweg te ingrijpend in alle processen die de bestaande data oplossingen ondersteunen. Daarnaast hebben organisaties daar al veel tijd en geld in geïnvesteerd, iets wat je niet zomaar teniet wilt doen.
Echter, wanneer er gestart wordt met het ontwikkelen van een nieuw data platform is het lakehouse absoluut het overwegen waard. Het is voor data gedreven organisaties de ideale architectuur omdat Business Intelligence, Data Science, Artificial Intelligence en Machine Learning allemaal kunnen plaatsvinden binnen een geïntegreerd platform. De techniek heeft zich binnen het Microsoft Azure platform inmiddels bewezen en is door het continu door ontwikkelen toekomstbestendig.
Wat dat betreft concludeer ik dat het lakehouse geen buzzword is maar een blijvend element in data en analytics omgevingen. Een recent artikel (d.d. 2 september 2021) waarin Databricks een nieuwe financieringsronde aankondigt van 1,6 miljard dollar om de verdere innovatie en ingebruikname van de data lakehouse-architectuur te versnellen onderstreept dat nog meer eens.
We gaan er op termijn dus nog veel van horen.
Kevin Konings

